Denormalising Your Rails Application - Dan Lucraft
As Dan pointed out, this is the first talk of the day on Rails! Dan works for Songkick, which is a social networking site for people who like live music. They've got a lot of data, some of which is quite expensive to generate. It involves a big slow join over five large tables, when extracting the data from an SQL database.
The obvious solution is to fragment cache the relevant content, but Songkick decided they didn't want to go that way. They don't mind if a user sometimes needs to wait a moment while a page is rendered, but Google is often the first "user" to see a lot of their pages. They don't want to serve pages slowly to Google. Nor do they want to have to re-generate all the HTML for 500,000 artists if they make a minor tweak to the HTML template. So caching doesn't really solve the problem.
Why not stash it in memcached? In addition to the reasons that they don't want to use fragment caching, Songkick want persistence. They decided to use MongoDB, having played around with a couple of alternatives.
Mongo doesn't have a schema. It's pretty quick (not as fast as memcached) and stores a lot of data in RAM. It's fairly mature, and the developers are very responsive. He says the docs are great.
Songkick have found the presenter pattern to be a good way to organise complex views, or forms, but they've never been totally clear on how they should be used. Do you have one presenter per form? Can they access the database directly? How do you organise them (by model, by view)? Using presenters with Mongo has made it quite clear how they should use them.
Here's my reproduction of the diagram Dan showed us, which explains how they've incorporated presenters and MongoDB into their Rails app:
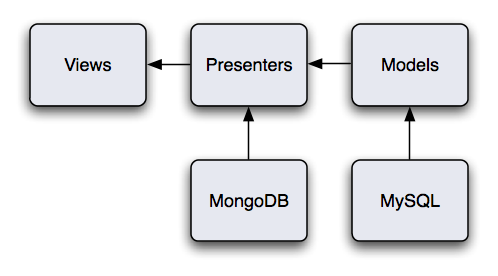
In the future the portion of the Songkick site that runs off MySQL and model objects may be droped entirely.
module Presenters::Artists
class AttendancePresenter
include Silo::Store
silo :collection => "articst_atendance", :id => lambda { @artist.id }
def initialize(artist)
@artist = artist
end
def total_num_users_seen_live
@artist.total_num_users_seen_live
end
silo_method :total_num_users_seen_live
def top_users_seen_live
@artist.top_useres.seen_live
end
silo_method :top_useres.seen_live
end
Note that the presenter has the same API as the model, so the view won't be able to tell the difference.
When defining the silo the collection is somewhat synonymous with the idea of a table.
The silo_method class methods are operating in a similar manner to the memoize method in ActiveSupport; it will return data from Mongo if it's available, or revert to asking the model object if it's not already there. The result is then stored in Mongo so it will be available next time you need the information.
How do you expire the cache? Enter the Silovator, stage left...
class ArtistObserver
observe Artist
def after_create(artist)
Silo.generate(presenter_for(artist))
end
def after_destroy(artist)
Silo.remove(presenter_for(artist))
end
end
This is nice, but it doesn't scale. Songkick may need to update thousands of documents as a result of one user action, so they need to run the update outside of the request/response cycle. They run the observer above in a background process.
In the Rails app they hook up their observers:
AsynchronousObserver.listen(Artist)
In the back end there's an observer that looks a bit like this:
class AttendanceSilovator < AsyncObserver
listen :create, Artist do
Silo.generate(presenter_for(artist))
end
listen :destroy, Artist do
Silo.remove(presenter_for(artist))
end
end
The AsyncObserver objects have access to a feed of all create/read/update or delete (CRUD) operations that occur in their system; they're broadcast over AMQP whenever anything changes on their system.
I'm not sure if I've explained enough of what Dan has been showing us here for you to follow along, but it's a highly scalable approach to handling huge amounts of data behind a Rails app.
As a way to cache data that is expensive to calculate, this approach strikes me as being insanely-good.
Dan has a blog and can also be found on Twitter (@danlucraft). Maybe he'll post his slides somewhere if you ask him nicely...
More talks from Ruby Manor
- Browser Level Testing - Martin Kleppmann
- Data Visualisation with Ruby - Chris Lowis
- gem that - James Adam
- Introduction to Rango - Jakub Šťastný
- Ruby and Cocoa - James Mead
- RubyGoLightly - Eleanor McHugh
- Secrets of the Standard Library - Paul Battley
- Short Order Ruby - Ben Griffiths
- Testing Third Party HTTP APIs - Richard Livsey and Bartosz Blimke
- The Joy of Painting with Ruby - Jason Cale
- Ruby Manor 2008 morning session and afternoon session